
Go to the next section.
(with contributions from Doug Cutting, Frank Halasz, and Denis Seversen)
(typeset 21 January 1999)
Copyright (C) 1991--1998 Xerox Corporation
All Rights Reserved.
@defcodeindex ft @defcodeindex vt @defcodeindex et @defcodeindex mt @defcodeindex tt @defcodeindex dt
This document describes version 2.0alpha14 of the Inter-Language Unification (ILU) system.
Lots of people contributed significant amounts of code to the ILU system, including (alphabetically): Joachim Achtzehnter, Judy Anderson, Antony Courtney, Doug Cutting, Mark Davidson, Ken Fishkin, Frank Halasz, Scott Hassan, Rob Head, Chris Jacobi, Bill Janssen, Swen Johnson, Dan Larner, Martin von Loewis, Bill Nell, Paula Newman, Ansgar Rademacher, Dennis Seversen, Bridget Spitznagel, Mike Spreitzer, Owen Taylor, Farrell Wymore, and Rick Yardumian.
Many others have contributed in other ways, including our reviewers, alpha and beta testers, and regular users. The list includes (but is not limited to): Shridhar Acharya, Joachim Achtzehnter, Judy Anderson, Maria Perez Ayo, Mike Beasley, Erik Bennett, Dan Brotsky, David Brownell, Bruce Cameron, George Carrette, Philip Chou, Daniel W. Connolly, Antony Courtney, Doug Cutting, Mark Davidson, Jim Davis, Larry Edelstein, Paul Everitt, Bill Fenner, Josef Fink, Jeanette Figueroa, James Flagg, Steve Freeman, Mark Friedman, Jim Gettys, Gabriel Sanchez Gutierrez, Jun Hamano, Bruno Haible, Scott W. Hassan, Carl Hauser, Rob Head, Michi Henning, Andrew Herbert, Angie Hinrichs, Ben Hurwitz, Roberto Invernici, Christian Jacobi, Swen Johnson, Gabor Karsai, Nobu Katayama, Dan `Bud' Keith, Sangkyun Kim, Ted Kim, Don Kimber, Steve Kirsch, Dan Larner, Carsten Malischewski, Larry Masinter, Fernando D. Mato Mira, Fazal Majid, Steven D. Majewski, Fernando D. Mato Mira, Michael McIlrath, Scott Minneman, Masashige Mizuyama, Curtis McKelvey, Chet Murthy, Farshad Nayeri, Bill Nell, Les Niles, T. Owen O'Malley, Annrai O'Toole, Andreas Paepcke, Jan Pedersen, Karin Petersen, Steve Putz, George Robertson, Joerg Schreck, Ian Smith, Bridget Spitznagel, Peter Swain, Marvin Theimer, Lindsay Todd, P. B. Tune, Bill Tutt, Kevin Tyson, Bill van Melle, Guido van Rossum, Brent Welch, Jody Winston, Rick Yardumian.
ILU is primarily about interfaces between units of program structure; we call these units modules. The notion is that each module enscapsulates some logical part of a program, that has high `cohesiveness' internally, and low `coupling' to other parts of the program. ILU provides you with a way of writing down an object-oriented interface to the module; that is, a set of object types and other types, constants, and exceptions that another module would use to communicate with it. This interface can then be processed by various ILU tools to implement that communication.
ILU allows many different binding relationships between modules. The modules can be parts of one program instance, all written in the same language; they can be parts written in different languages, sharing runtime support in one memory image; they can be parts running in different program instances on different machines (on different sides of the planet). A module could even be a distributed system implemented by many program instances on many machines. A particular module might be part of several different program instances at the same time. ILU does all the translating and communicating necessary to use all these kinds of modules in a single program. It optimizes calls across module interfaces to involve only as much mechanism as necessary for the calling and called modules to interact. In particular, when the two modules are in the same memory image and use the same data representations, the calls are direct local procedure calls -- no stubs or other RPC mechanisms are involved. The notion of a `module' should not be confused with the independent concept of a program instance; by which we mean the combination of code and data running in one memory image. A UNIX process is (modulo the possibilities introduced by the ability, in some UNIX sytems, to share memory between processes) an example of a program instance.
Because ILU standardizes many of the issues involved in providing proper inter-module independence, such as memory management and error detection and recovery strategies, it can be used to build language-independent class libraries, collections of re-usable object definitions and implementations. Because one of the design goals of ILU was to use existing standards for various pieces, rather than inventing anything new, ILU can be used to implement ONC RPC or Xerox Courier services, or clients for existing ONC RPC or Xerox Courier services. ILU also includes an implementation of the Object Management Group's CORBA Internet Inter-Orb Protocol (IIOP), and can be used to write CORBA services or clients, as well.
The approach used by ILU is one common to standard RPC systems such as Sun's ONC RPC, Xerox's Courier, and most implementations of OMG's CORBA. An interface is described once in some `language-neutral' interface specification language. Types and exceptions are described; exported functionality is specified by defining methods on object types. Tools are then run against the interface description to produce stubs for particular programming languages; these stubs can bind to, call, and be called from stubs generated from the same interface description for a different programming language. The stub code is then linked with the application code, some language-specific code containing any necessary ILU support for that programming language, and the ILU kernel library, which is code written in ANSI C. The following diagram illustrates the process:
Several modules may be linked together, for a standalone use. ILU stubs are generated in such a way that applications which link a caller and callee written in the same language directly together suffer no calling overhead. This makes ILU useful for defining interfaces between modules even in programs that do not use RPC.
Different modules of the program may be written in different programming languages. These can either be linked together in the same address space, if the runtimes of the different languages allow that, or they can be used to make separate network servers and clients. In the case of a network service, the memory layout for the program would be something like
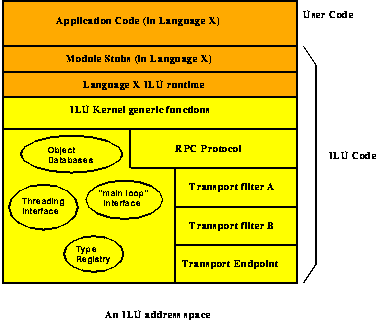
ILU is object-oriented. By this, we mean that object types serve as the primary encapsulation mechanism in ILU. All functionality is exported from a module as methods that can be invoked on an instance of some object type, rather than as simple procedures. The object instance provides the context within which methods are executed. The object type system provides subtyping (`inheritance' of interfaces (ILU does not address object implementation)), to aid in structuring of interfaces.
With respect to a particular ILU object instance, a module is called the server if it implements the methods of that object, or a client if it calls, but does not implement, the methods of that object. One module can thus be a client of one object, and the server of another. An ILU object can be passed as a parameter to or result of a method call, and can be (in) the parameter to an exception. An object may be passed from its server to a client, from a client to its server, or between two clients, in any of the above three kinds of position. Unlike some RPC systems, there can be multiple ILU objects of the same type, even on one machine, even within one program instance.
For a given ILU object, there will, in general, be multiple language-specific objects; each is an "object" in one of the programming languages used in the system. One language-specific object, designated the true object, actually provides the implementation of the ILU object; it is thus part of the server module. The true object's methods are written by the programmer, not generated by ILU. The other language-specific objects are surrogate objects; their methods are actually RPC stubs (generated by ILU) that call on the true object. A surrogate object is used by a client module when the server module is in a different program instance or uses different data representations.
Each instance in an ILU address space is associated with a kernel server, a construct which manages a group of objects. Kernel servers are found in both client and server modules. Each kernel server has a server ID, a universally unique string ID. The server ID makes up part of the object ID of the instances supported by the server. Some kernel servers contain only surrogate instances, and are called surrogate servers; others contain both surrogate and true instances, and are called true servers.
Kernel servers serve as the locus of communication between two address spaces. A true server may have a number of ports associated with it; a port is a mechanism by which other address spaces can interact with objects in this address space. Other address spaces use the port by creating a surrogate server which mirrors the true server, and opening a connection from the surrogate server to the true server. Calls from surrogate instances on true instances are carried along this connection. A true server may have multiple ports, each of which may provide connectability via different RPC protocols or transport mechanisms.
The object model specified here provides for multiple interface inheritance. It is intended that the subtype provide all the methods described by its supertypes, plus possibly other methods described directly in the subtype description. It is expected that in languages which support multiple-inheritance object models, that an ILU inheritance tree will be reflected in the language-specific inheritance tree. In a single-inheritance language, or a non-object-oriented one, an ILU-specific multiple-(interface-)inheritance object system must be embedded.
In the ILU type system, the only subtyping questions that arise are between two object types. This is because ILU employs only those OOP features common to all languages supported.
Subtyping in ILU is based on structure and name; we include the names in the structure, and thus need only talk about structure. An object type declaration of the form defined later constructs a structure of the form
(OBJTYPE
SINGLETON: singleton-protocol-info
OPTIONAL: Boolean
COLLECTIBLE: Boolean
AUTHENTICATION: authentication-type
SUPERTYPES: supertype-structure, ...
METHODS: method-structure, ...
LEVEL-BRANDS: (interface-name, interface-brand,
type-name, type-brand))
Structure A is a subtype of structure B iff either (1) A and B are equal structures, or (2) one member of A's supertype-structures is a subtype of B.
Note that the level-brands include the interface name and (optional) brand, as well as the name and (optional) brand of the type being declared. Thus, two declarations of subtypes of the same type normally create distinct subtypes, because they would declare types of different names, or in interfaces with different names. When the interface name and the type name are the same, this does not cause a distinction, although other structural differences might. If the programmer wants to indicate that there's a semantic distinction, even though it doesn't otherwise show up in the structure, s/he can use different interface brands and/or different type brands. These distinctions can be made between declarations in different files, or between successive versions of a declaration in a file that's been edited.
Many existing RPC protocols and servers do not have the notion of multiple instances of a type co-existing at the same server, so cannot use the instance discrimination information passed in ILU procedure calls. To support the use of these protocols and servers, we introduce the notion of a singleton object type, of which there is only one instance (of each singleton type) at a kernel server. Note that because a single address space may support multiple kernel servers, this means that in a single address space, there may be multiple instances of the same singleton type. When a method is being called on an instance of a singleton type, no instance discrimination information is passed. Singleton types may not be subclassed.
To use (e.g., call the methods of) an ILU object, a client must first obtain a language-specific object for that ILU object. This can be done in one of two ways: (1) the client can call on a language-specific object of a different ILU object to return the object in question (or receive the object in a call made on the client, or in the parameter of an exception caught and handled by the client); or (2) certain standard facilities can be used to acquire a language-specific object given either addressing or naming information about the ILU object. The addressing information is called a string binding handle (SBH), and the ILU runtime library includes a procedure to acquire a language-specific object given a string binding handle for an ILU object (in strongly-typed languages, this procedure is typed to return an object of the base type common to all ILU objects in that language).
Every creation of a surrogate instance implies communication with the server module, and binding of the surrogate instance to the true instance. ILU may attempt to perform this communication when it is actually necessary, rather than immediately on surrogate instance creation.
The process of creating an instance may bootstrapped via a name
service, such as the PARC Name-and-Maintenance-Server
(NMS), which allows servers to register instances on a
net-wide basis. A server registers a mapping from naming information to
a string binding handle. The client-side stubs for an interface include
a procedure that takes naming information, looks up the corresponding
string binding handle in the name service, and calls the above-mentioned
library routine to map the SBH to a language-specific object.
Alternatively, a client can do those steps itself, using an ILU
runtime library procedure to acquire a language-specific object for the
name service.
In ILU, there is a string-based representation for a reference to an object. That representation consists of a single string, called a string binding handle. ILU uses string binding handles when marshalling object references for RPC. ILU also allows applications to interconvert between objects and string binding handles. This is necessary when dealing with name services, and useful in other circumstances.
A string binding handle contains several different pieces of information:
The server ID, instance handle, and MSTID may each contain any ASCII character other than NUL. They are composed into the string binding handle according the the IETF rules for URLs, but the precise form of the URL is not specified here. (In versions of ILU before 2.0, string binding handles had a completely different syntax.)
The pair (server ID, instance handle) are also
known as the object ID (or OID) of the object, because together they form
a universally unique ID for the object.
The contact info part contains one or more contact info sequences, each describing one particular way of communicating with the object's kernel server. Each contact info sequence consists of a series of fields. The first field is known as the protocol info, and names a particular RPC protocol, and any parameters that might influence the way in which this protocol would be used. Each of the succeeding fields specifies transport info, which defines a way of transforming or communicating data, and any parameters which might influence that transport method. There may be many sequences of contact info in any one string binding handle (but ILU currently ignores all but the first).
Some ILU object instances may have implementation
dependencies on private communication with other instances. For
example, imagine an object type time-share-system, which
provides the method ListUsers(), which returns a list of
"user" instances. Imagine that time-share-system also
provides the method SetUserPriority(u : user, priority : integer).
We would like to be able to provide some assurance that
the user instance used as a parameter to SetUserPriority is an
instance returned from a call to ListUsers on the same instance
of a time-share-system, because the way in which
SetUserPriority is implemented relies on the user being a user
of that particular time-share-system.
The ILU model provides the notion of a sibling object. Two instances are siblings if their methods are handled by the same kernel server. Instances that are non-discriminator parameters to methods may be specified in ISL as having to be siblings of the discriminator.
True objects may either be created explicitly, or upon arrival of calls on them. The second option is exercised via a feature currently called object tables (from "hash tables", since they map a string, the instance handle, to an object -- "object factories" might be a less surprising term). After the object table creates an object, the server module then continues to manage the object's existence -- in the same way(s) it manages other objects it creates. This means a server need not hold in memory all of its objects at once, which may be quite important.
A true kernel server may optionally include an object table, whose job is to map an instance handle (see section String Binding Handle) to the object it identifies. ILU's runtime will consult the object table when a call is received for an object not currently reified. The object table can either explicitly create the named object, or refuse (thus declaring the instance handle invalid).
This mapping operation is invoked with certain of the ILU
runtime's mutexes (see section Thread Synchronization) held, because it is
an extension of a delicate part of that runtime. The server's mutex is
held in all cases, and the global mutex "gcmu" is also held if the
resulting object is expected to be of a COLLECTIBLE type. The
fact that these mutexes are held restricts what an application can do
inside this mapping procedure.
It is sometimes useful to have a `dummy' true kernel server, that will redirect any requests
to it to a real true kernel server somewhere else. This can be used for load balancing,
automatic start-up of services, implementation of a redirecting name service, code migration, and other
various purposes. ILU supports this via a mechanism called server relocation.
This mechanism allows a function to be associated with a true kernel server, which is called
when a request arrives at that kernel server over a connection which uses a relocating protocol.
A relocating protocol is a protocol that carries relocation requests, such as the CORBA IIOP,
or the HTTP-NG w3ng protocol. The relocation function
returns new contact info for the kernel server, which is sent back to the caller.
The caller then closes the existing connection and opens a new connection according to the specified contact info.
A simple form of garbage collection is defined for ILU objects. If an object type is tagged as being collectible, a server that implements objects of that type expects clients holding surrogate instances to register with it, passing an instance of a callback object. When a client finishes with the surrogate, the client unregisters itself. Thus the server may maintain a list of clients that hold surrogate instances. If no client is registered for an object, and the object has been dormant (had no methods called on it) for a period of time T1, the server may feel free to garbage collect the instance. T1 is determined by human concerns, not network performance: T1 is set long enough to allow useful debugging of a client.
To deal with possible failure of a client process, we introduce another time-out parameter. If an instance with registered clients has been dormant for a period of time T2, the server uses the callback instance associated with each client to see if the client still exists. If the client cannot be contacted for the callback, the server may remove it from the list of registered clients for that instance.
If a client calls a method on a surrogate instance of a true instance which
has been garbage-collected (typically because of partitioning), it will
receive the ilu.ProtocolError exception, with detail code
ilu.NoSuchInstanceAtServer.
ILU does not (directly) expose to the application programmer any notion of "connections". That is, the called module has no pointer back to the caller, and no notion of how to do anything with the caller aside from returning a result message. Credentials passed in the request message can identify the caller, but not necessarily the location the call is made from. Protocols that need such information should pass it explicitly as an argument (an instance of an object type with methods defined on it) to the method.
ILU's mechanisms avoid introducing blocking into a distributed program. This is because ILU does not try to track the identity of a thread of execution as it crosses program boundaries. So if ILU were to make one call wait for the completion of another, this would be a potential cause of deadlock.
It is possible for the programmer to explicitly inform ILU that one call's execution is not necessary for the completion of another. This is done indirectly, via a concept called a pipeline. A client can create a pipeline (any number, actually), and associate any collection of its calls with a pipeline (at most one pipeline per call). Making such associations asserts to ILU that none of the calls is needed for any other of them to complete. This allows ILU to block some of them until others complete.
Which will be blocked, and why would a client want to do this to itself? The answer has to do with connections. You remember, those things the previous section says are not exposed to applications. It's true that they're not directly exposed. But we'll admit here that they exist, and consume resources. Sometimes it's important to minimize those resources. When using a non-concurrent RPC protocol, ILU avoids introducing blocking by opening as many parallel connections as the client has concurrent calls to the same server. Some clients would prefer that their concurrent calls block instead of consume multiple connections. Such clients can use pipelines to enable this behavior.
ILU does not normally guarantee that the server application will receive calls in the same order that the client makes them (of course, ILU doesn't promise to violate causality -- it just doesn't do any work to give you anything more). This is a particularly interesting issue when making a series of asynchronous calls (because there are no replies to carry causality). You might think that when using a transport, such as TCP, that guarantees ordering, call order preservation will follow as a consequence. But it's not that simple (i.e., ILU may use multiple connections in parallel and series, and TCP provides no ordering guarantees between connections).
However, it's possible for a client application to explicitly request a guarantee of call order preservation for a given collection of its calls. This is done indirectly through an object called a serializer. A serializer represents an instance of the serialization guarantee. This guarantee is with respect to a particular server and collection of calls. It guarantees that those calls will be received by the server application in the same order as they were made by the client application -- except that client calls that return after a barrier call may be received before client calls that return before that same barrier call. A barrier call is one that raises the BARRIER exception, which is an ILU-specific system exception. Remember that ASYNCHRONOUS calls do return, they just do so particularly quickly.
Special considerations apply when these calls are issued concurrently. Two calls are considered to have been issued concurrently if each call is initiated before the other returns. In a multi-threaded runtime, they client may issue concurrent calls under the same instance of the serialization guarantee, and the ILU runtime will put them in some serial order. Note that for two concurrently issued calls, either: (a) the one put first is ASYNCHRONOUS, (b) they both are in the same pipeline, or (c) the one put second is delayed until the one put first returns. In a single-threaded runtime, the client may issue two calls "concurrently" (taking advantage of a nested main loop), but both will execute successfully only if the client is lucky; otherwise, the second one will raise the system exception BAD_PARAM with minor code ilu_bpm_serialConcurrent. Furthermore, when single-threaded, issuing concurrent calls under the same instance of the serialization guarantee but different pipelines will also cause some to raise BAD_PARAM/serialConcurrent.
A client can create any number of serializers, and associate each one of its calls with at most one serializer. This guarantee is only available for servers exported over non-concurrent RPC protocols and reliable transports. Due to current implementation limitations, the default port of the server must satisfy the protocol and transport restriction. If that port does not meet the protocol restriction, serialized calls will fail with the system exception INV_OBJREF with a minor code of ilu_iom_conc_serial (where no other error is noticed first)
In ILU, a call between address spaces involves sending an call message from the caller to the callee. The call message is usually sent immediately upon initiation of the call. However, there is a way for these call messages to be delayed and gathered into batches under application control. An application specifies this by use of a meta-object called a batcher. A given call may optionally be associated with a batcher, and a batcher may use either or both of two ways to specify when delivery of its buffered call messages should be initiated. The first method is by explicit application call to push the batcher. The second is by timeout: a call message's delivery is initiated at most some time constant past the time when composition of the call message completed. Which of these two ways are applicable is specified when the batcher is created, as is the timeout value (if any). Note that we speak here only of initiation of delivery, not receipt by any particular layer of the receiver. This feature involves only client-side mechanism, and so may be used with non-ILU servers.
ILU includes a simple binding/naming facility. It allows a module to publish an object, so that another module can import that object knowing only its object ID (as defined in section ILU Concepts). It is essentially just a way of binding a URN (the object's ID) to a URL (the object's string binding handle). The interface to this facility is deliberately quite simple; one reason is to allow various implementations.
The interface consists of three operations: Publish,
Withdraw, and Lookup. Publish takes one argument, an
ILU object. Publish returns a string that is needed to
successfully invoke Withdraw. Withdraw undoes the effects of
Publish, and takes two arguments: (1) the object in question, and
(2) the string returned from Publish. In some langauge mappings,
the string is not explicitly passed, but conveyed in the language
mapping's representation of ILU objects. Lookup takes two
arguments: an object ID and a type the identified object should have.
If the object with that ID is currently being published, and has the
given type (among others), Lookup returns that object.
The implementation of simple binding shipped with ILU can use either an ILU service, or a shared filesystem directory, to store information on the currently published objects. This choice must be specified at system configuration time. If the shared filesystem approach is used, this directory must be available by the same name, on all machines which wish to interoperate. The way in which clients interact with binding is the same, regardless of which approach is selected. See section Binding Names in ILU for more information on these implementations.
ILU uses the notion of an exception to signal errors between modules. An exception is a way of passing control outside the normal flow of control. It is typically used for handling of errors. The routine which detects the error signals an exception, which is caught by some error-handling mechanism. The exception type supported in ILU is a termination-model exception, in which the calling stack is unrolled back to the frame which defined the exception handler. Exceptions are signalled and caught using the native exception mechanisms for the servers and clients. A raised exception may carry a single parameter value, which is typed.
The type and exception model used by ILU is quite similar to that used by the Object Management Group's Common Object Request Broker Architecture (CORBA). We have in fact changed ILU in some ways to more closely match CORBA. Our tools will optionally parse the OMG's Interface Definition Language (OMG IDL) as well as ILU's ISL.
ILU also attempts to address issues that are already upon us, but are not addressed in CORBA 2.0, particularly a uniform way of indicating optional values, and distributed garbage collection.
ILU provides two different interface definition languages, OMG IDL and ILU ISL to enhance portability of ILU modules. The OMG IDL subset understood by ILU is a strict subset of OMG IDL; this means that any ILU modules developed using OMG IDL interfaces should be interoperable with any other CORBA system. Any non-CORBA extensions may only be expressed in ILU ISL, so that any modules which use these extensions must use ILU ISL to express their interfaces, thereby underlining the fact that these modules are not CORBA-compliant. We feel that this dual-interface-language approach will tend to enhance both portability and CORBA-compliance of ILU modules.
ILU does not yet provide some of the features required by a full CORBA implementation. Notably it does not provide a Dynamic Invocation Interface or Dynamic Server Interface, or implementations of either Interface Repository or Implementation Repository. It does not provide the Basic Object Adapter interface, either, but does provide an object adapter with most of the BOA's capabilities, except for those connected with the Interface Repository and/or Implementation Repository.
A number of concepts in CORBA that seem to require further
thought are not yet directly supported in ILU: the use of
#include (ILU uses a more limited notion of "import");
the notion of using an IDL "interface" as both an object
type and a name space (this seems to be a "tramp idea" from the
language C++; in ILU the "interface" defines a
name space, and the object type defines a type); the notion that all BOA
objects are persistent (in ILU, the question of whether an
object is persistent is left up to that object's implementation); the
notion that type definitions can exist outside the scope of any module
or namespace (in ILU, all definitions occur in some interface).
Currently, there is no support in ILU for CORBA
contexts.
Go to the next section.